Query foundation models
In this article, you learn how to format query requests for foundation models and send them to your model serving endpoint. You can query foundation models that are hosted by Databricks and foundation models hosted outside of Databricks.
For traditional ML or Python models query requests, see Query serving endpoints for custom models.
Mosaic AI Model Serving supports Foundation Models APIs and external models for accessing foundation models. Model Serving uses a unified OpenAI-compatible API and SDK for querying them. This makes it possible to experiment with and customize foundation models for production across supported clouds and providers.
Mosaic AI Model Serving provides the following options for sending scoring requests to endpoints that serve foundation models or external models:
| Method | Details |
|---|---|
| OpenAI client | Query a model hosted by a Mosaic AI Model Serving endpoint using the OpenAI client. Specify the model serving endpoint name as the model input. Supported for chat, embeddings, and completions models made available by Foundation Model APIs or external models. |
| SQL function | Invoke model inference directly from SQL using the ai_query SQL function. See Query a served model with ai_query. |
| Serving UI | Select Query endpoint from the Serving endpoint page. Insert JSON format model input data and click Send Request. If the model has an input example logged, use Show Example to load it. |
| REST API | Call and query the model using the REST API. See POST /serving-endpoints/{name}/invocations for details. For scoring requests to endpoints serving multiple models, see Query individual models behind an endpoint. |
| MLflow Deployments SDK | Use MLflow Deployments SDK’s predict() function to query the model. |
| Databricks Python SDK | Databricks Python SDK is a layer on top of the REST API. It handles low-level details, such as authentication, making it easier to interact with the models. |
Requirements
- A model serving endpoint.
- A Databricks workspace in a supported region.
- To send a scoring request through the OpenAI client, REST API or MLflow Deployment SDK, you must have a Databricks API token.
As a security best practice for production scenarios, Databricks recommends that you use machine-to-machine OAuth tokens for authentication during production.
For testing and development, Databricks recommends using a personal access token belonging to service principals instead of workspace users. To create tokens for service principals, see Manage tokens for a service principal.
Install packages
After you have selected a querying method, you must first install the appropriate package to your cluster.
- OpenAI client
- REST API
- MLflow Deployments SDK
- Databricks Python SDK
To use the OpenAI client, the databricks-sdk[openai] package needs to be installed on your cluster. Databricks SDK provides a wrapper for constructing the OpenAI client with authorization automatically configured to query generative AI models. Run the following in your notebook or your local terminal:
!pip install databricks-sdk[openai]>=0.35.0
The following is only required when installing the package on a Databricks Notebook
dbutils.library.restartPython()
Access to the Serving REST API is available in Databricks Runtime for Machine Learning.
!pip install mlflow
The following is only required when installing the package on a Databricks Notebook
dbutils.library.restartPython()
The Databricks SDK for Python is already installed on all Databricks clusters that use Databricks Runtime 13.3 LTS or above. For Databricks clusters that use Databricks Runtime 12.2 LTS and below, you must install the Databricks SDK for Python first. See Databricks SDK for Python.
Query a chat completion model
The following are examples for querying a chat model. The example applies to querying a chat model made available using either of the Model Serving capabilities: Foundation Model APIs or External models.
For a batch inference example, see Perform batch LLM inference using ai_query.
- OpenAI client
- REST API
- MLflow Deployments SDK
- Databricks Python SDK
- LangChain
- SQL
The following is a chat request for the DBRX Instruct model made available by the Foundation Model APIs pay-per-token endpoint, databricks-dbrx-instruct in your workspace.
To use the OpenAI client, specify the model serving endpoint name as the model input.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
openai_client = w.serving_endpoints.get_open_ai_client()
response = openai_client.chat.completions.create(
model="databricks-dbrx-instruct",
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "What is a mixture of experts model?",
}
],
max_tokens=256
)
To query foundation models outside of your workspace, you must use the OpenAI client directly. You also need your Databricks workspace instance to connect the OpenAI client to Databricks. The following example assumes you have a Databricks API token and openai installed on your compute.
import os
import openai
from openai import OpenAI
client = OpenAI(
api_key="dapi-your-databricks-token",
base_url="https://example.staging.cloud.databricks.com/serving-endpoints"
)
response = client.chat.completions.create(
model="databricks-dbrx-instruct",
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "What is a mixture of experts model?",
}
],
max_tokens=256
)
The following example uses REST API parameters for querying serving endpoints that serve foundation models. These parameters are Public Preview and the definition might change. See POST /serving-endpoints/{name}/invocations.
The following is a chat request for the DBRX Instruct model made available by the Foundation Model APIs pay-per-token endpoint, databricks-dbrx-instruct in your workspace.
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": " What is a mixture of experts model?"
}
]
}' \
https://<workspace_host>.databricks.com/serving-endpoints/databricks-dbrx-instruct/invocations \
The following example uses the predict() API from the MLflow Deployments SDK.
The following is a chat request for the DBRX Instruct model made available by the Foundation Model APIs pay-per-token endpoint, databricks-dbrx-instruct in your workspace.
import mlflow.deployments
# Only required when running this example outside of a Databricks Notebook
export DATABRICKS_HOST="https://<workspace_host>.databricks.com"
export DATABRICKS_TOKEN="dapi-your-databricks-token"
client = mlflow.deployments.get_deploy_client("databricks")
chat_response = client.predict(
endpoint="databricks-dbrx-instruct",
inputs={
"messages": [
{
"role": "user",
"content": "Hello!"
},
{
"role": "assistant",
"content": "Hello! How can I assist you today?"
},
{
"role": "user",
"content": "What is a mixture of experts model??"
}
],
"temperature": 0.1,
"max_tokens": 20
}
)
The following is a chat request for the DBRX Instruct model made available by the Foundation Model APIs pay-per-token endpoint, databricks-dbrx-instruct in your workspace.
This code must be run in a notebook in your workspace. See Use the Databricks SDK for Python from a Databricks notebook.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ChatMessage, ChatMessageRole
w = WorkspaceClient()
response = w.serving_endpoints.query(
name="databricks-dbrx-instruct",
messages=[
ChatMessage(
role=ChatMessageRole.SYSTEM, content="You are a helpful assistant."
),
ChatMessage(
role=ChatMessageRole.USER, content="What is a mixture of experts model?"
),
],
max_tokens=128,
)
print(f"RESPONSE:\n{response.choices[0].message.content}")
To query a foundation model endpoint using LangChain, you can use the ChatDatabricks ChatModel class and specify the endpoint.
The following example uses the ChatDatabricks ChatModel class in LangChain to query the Foundation Model APIs pay-per-token endpoint, databricks-dbrx-instruct.
%pip install databricks-langchain
from langchain_core.messages import HumanMessage, SystemMessage
from databricks_langchain import ChatDatabricks
messages = [
SystemMessage(content="You're a helpful assistant"),
HumanMessage(content="What is a mixture of experts model?"),
]
llm = ChatDatabricks(endpoint_name="databricks-dbrx-instruct")
llm.invoke(messages)
The following example uses the built-in SQL function, ai_query. This function is Public Preview and the definition might change. See Query a served model with ai_query.
The following is a chat request for meta-llama-3-1-70b-instruct made available by the Foundation Model APIs pay-per-token endpoint, databricks-meta-llama-3-1-70b-instruct in your workspace.
The ai_query() function does not support query endpoints that serve the DBRX or the DBRX Instruct model.
SELECT ai_query(
"databricks-meta-llama-3-1-70b-instruct",
"Can you explain AI in ten words?"
)
As an example, the following is the expected request format for a chat model when using the REST API. For external models, you can include additional parameters that are valid for a given provider and endpoint configuration. See Additional query parameters.
{
"messages": [
{
"role": "user",
"content": "What is a mixture of experts model?"
}
],
"max_tokens": 100,
"temperature": 0.1
}
The following is an expected response format for a request made using the REST API:
{
"model": "databricks-dbrx-instruct",
"choices": [
{
"message": {},
"index": 0,
"finish_reason": null
}
],
"usage": {
"prompt_tokens": 7,
"completion_tokens": 74,
"total_tokens": 81
},
"object": "chat.completion",
"id": null,
"created": 1698824353
}
Query an embedding model
The following is an embeddings request for the gte-large-en model made available by Foundation Model APIs. The example applies to querying an embedding model made available using either of the Model Serving capabilities: Foundation Model APIs or external models.
- OpenAI client
- REST API
- MLflow Deployments SDK
- Databricks Python SDK
- LangChain
- SQL
To use the OpenAI client, specify the model serving endpoint name as the model input.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
openai_client = w.serving_endpoints.get_open_ai_client()
response = openai_client.embeddings.create(
model="databricks-gte-large-en",
input="what is databricks"
)
To query foundation models outside your workspace, you must use the OpenAI client directly, as demonstrated below. The following example assumes you have a Databricks API token and openai installed on your compute. You also need your Databricks workspace instance to connect the OpenAI client to Databricks.
import os
import openai
from openai import OpenAI
client = OpenAI(
api_key="dapi-your-databricks-token",
base_url="https://example.staging.cloud.databricks.com/serving-endpoints"
)
response = client.embeddings.create(
model="databricks-gte-large-en",
input="what is databricks"
)
The following example uses REST API parameters for querying serving endpoints that serve foundation models or external models. These parameters are Public Preview and the definition might change. See POST /serving-endpoints/{name}/invocations.
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{ "input": "Embed this sentence!"}' \
https://<workspace_host>.databricks.com/serving-endpoints/databricks-gte-large-en/invocations
The following example uses the predict() API from the MLflow Deployments SDK.
import mlflow.deployments
export DATABRICKS_HOST="https://<workspace_host>.databricks.com"
export DATABRICKS_TOKEN="dapi-your-databricks-token"
client = mlflow.deployments.get_deploy_client("databricks")
embeddings_response = client.predict(
endpoint="databricks-gte-large-en",
inputs={
"input": "Here is some text to embed"
}
)
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ChatMessage, ChatMessageRole
w = WorkspaceClient()
response = w.serving_endpoints.query(
name="databricks-gte-large-en",
input="Embed this sentence!"
)
print(response.data[0].embedding)
To use a Databricks Foundation Model APIs model in LangChain as an embedding model, import the DatabricksEmbeddings class and specify the endpoint parameter as follows:
%pip install databricks-langchain
from databricks_langchain import DatabricksEmbeddings
embeddings = DatabricksEmbeddings(endpoint="databricks-gte-large-en")
embeddings.embed_query("Can you explain AI in ten words?")
The following example uses the built-in SQL function, ai_query. This function is Public Preview and the definition might change. See Query a served model with ai_query.
SELECT ai_query(
"databricks-gte-large-en",
"Can you explain AI in ten words?"
)
The following is the expected request format for an embeddings model. For external models, you can include additional parameters that are valid for a given provider and endpoint configuration. See Additional query parameters.
{
"input": [
"embedding text"
]
}
The following is the expected response format:
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": []
}
],
"model": "text-embedding-ada-002-v2",
"usage": {
"prompt_tokens": 2,
"total_tokens": 2
}
}
Check if embeddings are normalized
Use the following to check if the embeddings generated by your model are normalized.
import numpy as np
def is_normalized(vector: list[float], tol=1e-3) -> bool:
magnitude = np.linalg.norm(vector)
return abs(magnitude - 1) < tol
Query a text completion model
- OpenAI client
- REST API
- MLflow Deployments SDK
- Databricks Python SDK
- SQL
Querying text completion models made available using Foundation Model APIs pay-per-token using the OpenAI client is not supported. Only querying external models using the OpenAI client is supported as demonstrated in this section.
To use the OpenAI client, specify the model serving endpoint name as the model input. The following example queries the claude-2 completions model hosted by Anthropic using the OpenAI client. To use the OpenAI client, populate the model field with the name of the model serving endpoint that hosts the model you want to query.
This example uses a previously created endpoint, anthropic-completions-endpoint, configured for accessing external models from the Anthropic model provider. See how to create external model endpoints.
See Supported models for additional models you can query and their providers.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
openai_client = w.serving_endpoints.get_open_ai_client()
completion = openai_client.completions.create(
model="anthropic-completions-endpoint",
prompt="what is databricks",
temperature=1.0
)
print(completion)
The following is a completions request for querying a completions model made available using external models.
The following example uses REST API parameters for querying serving endpoints that serve external models. These parameters are Public Preview and the definition might change. See POST /serving-endpoints/{name}/invocations.
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{"prompt": "What is a quoll?", "max_tokens": 64}' \
https://<workspace_host>.databricks.com/serving-endpoints/<completions-model-endpoint>/invocations
The following is a completions request for querying a completions model made available using external models.
The following example uses the predict() API from the MLflow Deployments SDK.
import os
import mlflow.deployments
# Only required when running this example outside of a Databricks Notebook
os.environ['DATABRICKS_HOST'] = "https://<workspace_host>.databricks.com"
os.environ['DATABRICKS_TOKEN'] = "dapi-your-databricks-token"
client = mlflow.deployments.get_deploy_client("databricks")
completions_response = client.predict(
endpoint="<completions-model-endpoint>",
inputs={
"prompt": "What is the capital of France?",
"temperature": 0.1,
"max_tokens": 10,
"n": 2
}
)
# Print the response
print(completions_response)
TThe following is a completions request for querying a completions model made available using external models.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ChatMessage, ChatMessageRole
w = WorkspaceClient()
response = w.serving_endpoints.query(
name="<completions-model-endpoint>",
prompt="Write 3 reasons why you should train an AI model on domain specific data sets."
)
print(response.choices[0].text)
The following example uses the built-in SQL function, ai_query. This function is Public Preview and the definition might change. See Query a served model with ai_query.
SELECT ai_query(
"<completions-model-endpoint>",
"Can you explain AI in ten words?"
)
The following is the expected request format for a completions model. For external models, you can include additional parameters that are valid for a given provider and endpoint configuration. See Additional query parameters.
{
"prompt": "What is mlflow?",
"max_tokens": 100,
"temperature": 0.1,
"stop": [
"Human:"
],
"n": 1,
"stream": false,
"extra_params":
{
"top_p": 0.9
}
}
The following is the expected response format:
{
"id": "cmpl-8FwDGc22M13XMnRuessZ15dG622BH",
"object": "text_completion",
"created": 1698809382,
"model": "gpt-3.5-turbo-instruct",
"choices": [
{
"text": "MLflow is an open-source platform for managing the end-to-end machine learning lifecycle. It provides tools for tracking experiments, managing and deploying models, and collaborating on projects. MLflow also supports various machine learning frameworks and languages, making it easier to work with different tools and environments. It is designed to help data scientists and machine learning engineers streamline their workflows and improve the reproducibility and scalability of their models.",
"index": 0,
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 5,
"completion_tokens": 83,
"total_tokens": 88
}
}
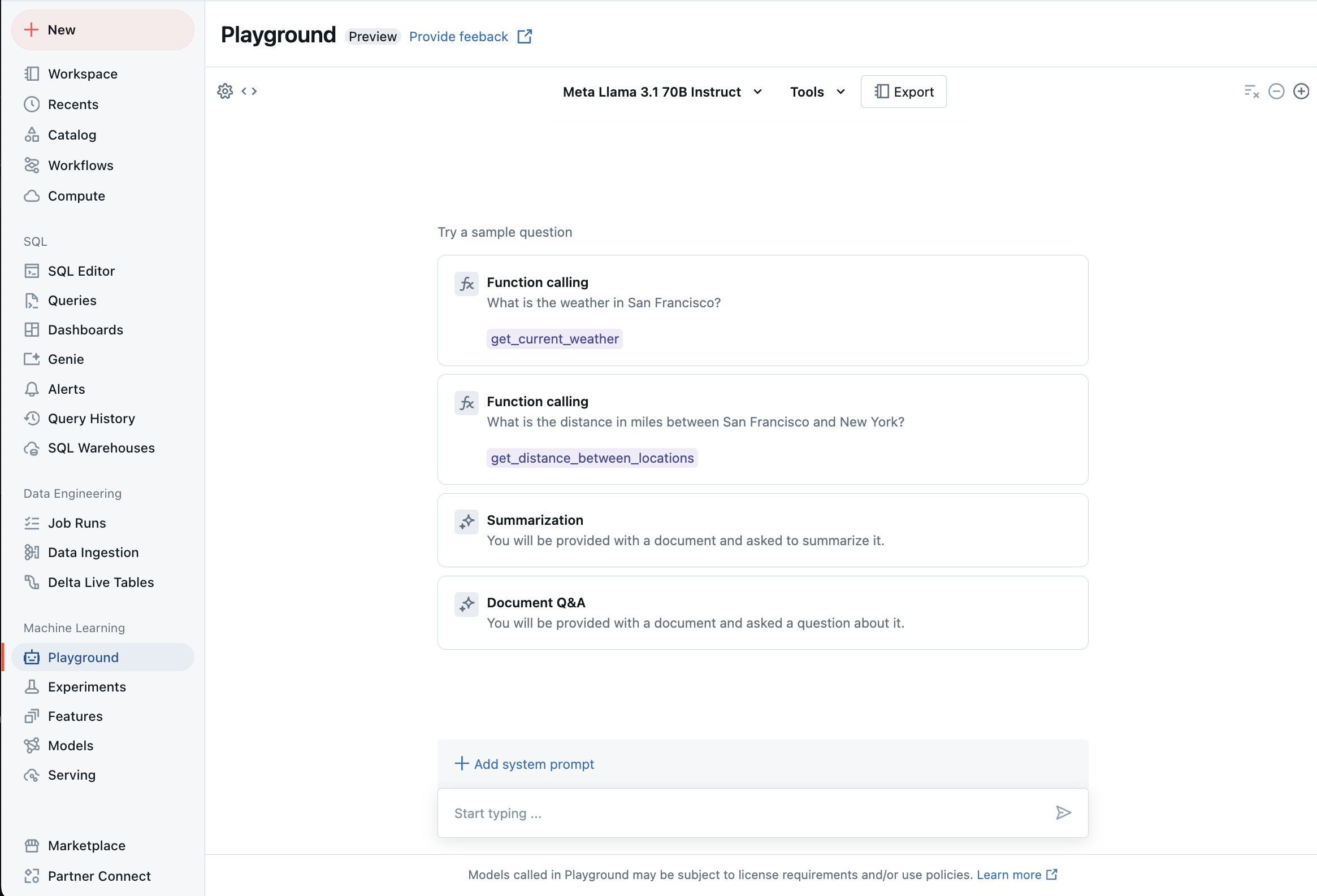
Chat with supported LLMs using AI Playground
You can interact with supported large language models using the AI Playground. The AI Playground is a chat-like environment where you can test, prompt, and compare LLMs from your Databricks workspace.
Additional resources
- Monitor served models using AI Gateway-enabled inference tables
- Perform batch LLM inference using
ai_query - Databricks Foundation Model APIs
- External models in Mosaic AI Model Serving
- Tutorial: Create external model endpoints to query OpenAI models
- Supported models for pay-per-token
- Foundation model REST API reference