Choose a development language
Databricks supports the use of different programming languages for development and data engineering. This article outlines the available options, where those languages can be used, and their limitations.
Recommendations
Databricks recommends Python and SQL for new projects:
- Python is a very popular general-purpose programming language. PySpark DataFrames make it easy to create testable, modular transformations. The Python ecosystem also supports a wide range of libraries supports a wide range of libraries for extending your solution.
- SQL is a very popular language for managing and manipulating relational datasets by performing operations like querying, updating, inserting, and deleting data. SQL is a good choice if your background is primarily in databases or data warehousing. SQL can also be embedded in Python using
spark.sql.
The following languages have limited support, so Databricks does not recommend them for new data engineering projects:
- Scala is the language that is used for the development of Apache Spark™.
- R is only fully supported in Databricks notebooks.
Language support also varies depending on the feature capabilities used to build data pipelines and other solutions. For example, Delta Live Tables supports Python and SQL, whereas workflows allows you to create data pipelines using Python, SQL, Scala, and Java.
Other languages can be used to interact with Databricks to query data or perform data transformations. However, these interactions are primarily in the context of integrations with external systems. In these cases, a developer can use almost any programming language to interact with Databricks through the Databricks REST API, ODBC/JDBC drivers, specific languages with Databricks SQL connector support (Go, Python, Javascript/Node.js), or languages that have Spark Connect implementations, such as Go and Rust.
Workspace development vs local development
You can develop data projects and pipelines using the Databricks workspace or an IDE (integrated development environment) on your local machine, but starting new projects in the Databricks workspace is recommended. The workspace is accessible using a web browser, it provides easy access to data in Unity Catalog, and it supports powerful debugging capabilities and features such as the Databricks Assistant.
Develop code in the Databricks workspace using Databricks notebooks or the SQL editor. Databricks notebooks support multiple programming languages even inside the same notebook, so you can develop using Python, SQL, and Scala.
There are several advantages of developing code directly in the Databricks workspace:
- The feedback loop is faster. You can immediately test written code on real data.
- The built-in, context-aware Databricks Assistant can speed up the development and help fix problems.
- You can easily schedule notebooks and queries directly from the Databricks workspace.
- For Python development, you can correctly structure your Python code by using files as Python packages in a workspace.
However, local development within an IDE provides the following advantages:
- IDEs have better tools for working with software projects, such as navigation, code refactoring, and static code analysis.
- You can choose how you control your source, and if you use Git, more advanced functionality is available locally than in the workspace with Git folders.
- There is a wider range of supported languages. For example, you can develop code using Java and deploy it as a JAR task.
- There is better support for code debugging.
- There is better support for working with unit tests.
Language selection example
Language selection for data engineering is visualized using the following decision tree:
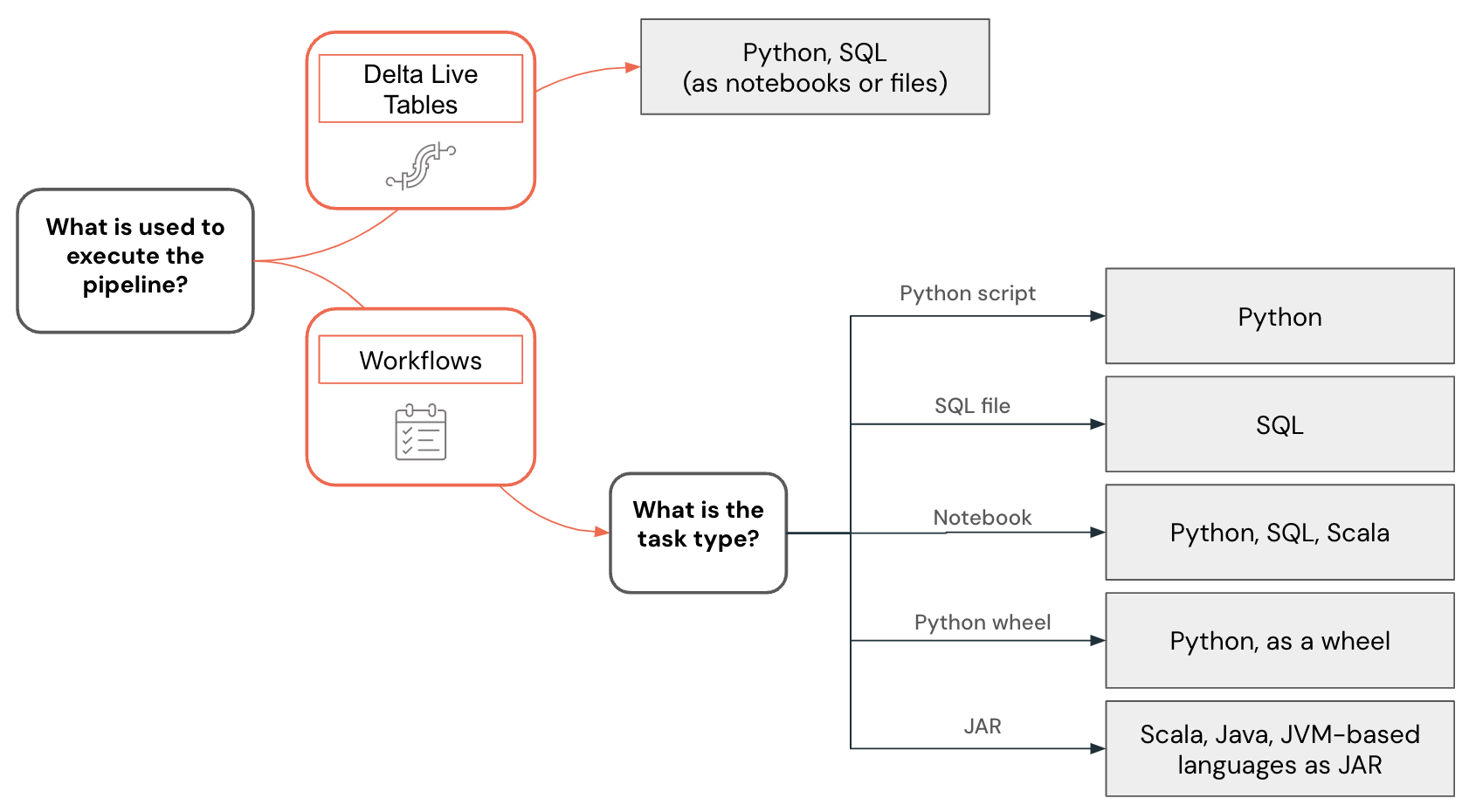
Developing Python code
The Python language has first-class support on Databricks. You can use it in Databricks notebooks, Delta Live Tables and workflows, to develop UDFs, and also deploy it as a Python script and as wheels.
When developing Python projects in the Databricks workspace, whether as notebooks or in files, Databricks provides tools such as code completion, navigation, syntax validation, code generation using Databricks Assistant, interactive debugging, and more. Developed code can be executed interactively, deployed as a Databricks workflow or a Delta Live Tables pipeline, or even as a function in Unity Catalog. You can structure your code by splitting it into separate Python packages that can then be used in multiple pipelines or jobs.
Databricks provides an extension for Visual Studio Code and JetBrains offers a plugin for PyCharm that allow you to develop Python code in an IDE, synchronize code to a Databricks workspace, execute it inside the workspace, and perform step-by-step debugging using Databricks Connect. The developed code can then be deployed using Databricks Asset Bundles as a Databricks job or pipeline.
Developing SQL code
The SQL language can be used inside Databricks notebooks or as Databricks queries using the SQL editor. In both cases, a developer gets access to tools such as code completion, and the context-aware Databricks Assistant that can be used for code generation and fixing problems. The developed code can be deployed as a job or pipeline.
Databricks workflows also allow you to execute SQL code stored in a file. You can use an IDE to create these files and upload them to the workspace. Another popular use of SQL is in data engineering pipelines developed using dbt (data build tool). Databricks workflows supports orchestrating dbt projects.
Developing Scala code
Scala is the original language of Apache Spark™. It’s a powerful language, but it has a steep learning curve. Although Scala is a supported language in Databricks notebooks, there are some limitations related to how Scala classes and objects are created and maintained that may make development of complex pipelines more difficult. Typically IDEs provide better support for the development of Scala code, which can then be deployed using JAR tasks in Databricks workflows.
Next steps
- Develop on Databricks is an entry point for documentation about different development options for Databricks.
- The developer tools page describes different development tools that can be used to develop locally for Databricks, including Databricks Asset Bundles and plugins for IDEs.
- Develop code in Databricks notebooks describes how to develop in the Databricks workspace using Databricks notebooks.
- Write queries and explore data in the SQL editor. This article describes how to use the Databricks SQL editor to work with SQL code.
- Develop Delta Live Tables pipelines describes the development process for Delta Live Tables.
- Databricks Connect allows you to connect to Databricks clusters and execute code from your local environment.
- Learn how to use Databricks Assistant for faster development and to resolve code issues.